

The 3 Bottom-Line Commandments of IT

Steve Kay

There are 3 things that keep me up at night when I support and advise clients on their IT services and systems. I lay these out below and also provide an example scenario of a company that gets hit with preventable incident and how it impacts the bottom line.
Reliability
My number one rule of thumb is to eliminate any single point of failure wherever it is financially possible. There are so many inexpensive ways to drastically increase the uptime of your systems. We all just want to come into the office with things working right? The simplest of failures can cause significant outages resulting in lost revenue.
Add those extra parts!
Power supplies and hard drives in servers go bad more than any other part on your network because they are the most heavily utilized. The good thing is most systems support adding redundancy here. If cost is an issue, determine your most mission critical systems and beef these up first. Add the second power supply and choose the correct raid set for hard drives that meets both the performance you need as well as allowing for failures. A correctly provisioned server should be able to withstand a bad hard drive or two while you get them warrantied.
Implement additional paths!
We have all been there. The internet is out, and no one can work. The solution? Integrate multiple paths to the internet/branch offices. While we would all like to have multiple fiber connections from multiple carriers and advertising your DNS block with BGP to guarantee 100% uptime of all systems the cost of this can be significant. However, something as simple as a cable internet connection can give you partial functionality while your main carrier is resolving their issue. This may allow you to be able to file that important return or gate a case filed.
Add extra pieces!
I am a huge fan of redundant everything. One of the most critical places is at the edge. We now have redundant ISPs (see above) but our firewall just failed. The best design is an HA pair of firewalls. If one dies, the other one takes over. Or if you are feeling extra frisky, pay a little more and let them work in tandem. Trunk these back to a core switch with redundant everything (Fans, blades, UPS systems etc.)
Take it to the cloud!
Microsoft’s Azure and Amazon’s AWS are doing all the reliability for you. If you have a system that bandwidth concerns are not relevant, move it in the cloud. A good example of this is email. You can put in redundant paths for internet, but unless your MX records are being broadcast to all your providers, incoming mail will be down if your main provider goes down. The time for DNS to converge on the internet have drastically improved so it’s feasible to manually move these, but there is still that gap for outage. O365 is a prime example of a great solution. Your users will never know the difference and your reliability will be up toward the 100% mark and if worse comes to worse you can go work on a hotspot somewhere and have access to your email anywhere you have internet.
Scalability
Ok, you need a new server for example. What are you doing with it? If your vendor is nor asking that you are not talking to the right place. You are getting ready for a large capital purchase and you need to make sure it is going to last you till the next budget cycle (usually 5 years.) However, you want to appropriately size the unit, so it is not “over kill,” but still be able to expand the capacity if needed.
Memory capacity and storage are going to be your main concerns.
Those are the two items you will likely need to add more of before it is time to buy a new server again. While these are not cheap to add, they are much less expensive replacing the entire server early. Your vendor should work with you to see what you are using the system for and what the likelihood of growth to your organization or server needs will be. Regardless, the server should always have the availability for easy expansion. I have rarely seen a server just sit there and not need to be touched until 5 years later.
Virtualize!
A lot of the investment in your server is at the Operating System level. The amount of labor invested in installing and configuring the Server OS and associated applications and services can be significant. If you outgrow the hardware everything needs to be reconfigured on the new. There is a solution for that and it is to virtualize your servers. When they are virtualized, they are now hardware agnostic. If the OS is still in support, the virtual server can be easily migrated to new hardware. This also makes it much more dynamic to add storage and other resources on the fly. Network attached storage or storage area networks can really expand the performance and capacity of your systems allowing for greater scalability if your need is there and budget allows. Hey while we are at it and budgets no issue, lets set up a high availability virtualized platform that load balances across multiple servers.
Keeping up with the internet.
Bandwidth from ISPs keeps getting cheaper and faster. This is happening so quickly that your firewall can get outdated very quickly. As a consultant, I am routinely coming across newer firewalls that don’t support the bandwidth that is being fed to them. The necessity of the next gen firewall has become almost paramount in todays security views, but this also greatly impacts the ability to process incoming bandwidth and drive the need for more horsepower. When selecting your perimeter defenses, be sure to factor your near future bandwidth needs as they are sure to grow and make sure your firewall can scale with it.
Recovery
So, we all have servers and know we need to back them up. So often, I see organizations determining the backup strategy and sizing based off two things: price and bulk storage needs based off what it in use. Sadly, I have seen IT companies advise their clients on just these two factors as well. The most critical thing to think about this: “is the information I need going to be recoverable when I need it?” To calculate the ability to satisfy this, we need to determine two things: RTO and RPO.
Recovery Time Objective
How long can you stand to be down in the event of an outage. Most of the time I see IT vendors just recommending a backup system to satisfy data size and scheduling file level backups and restores. Hey, it’s proven and your data will likely be there when you go to get it but, what they didn’t tell you is that its going to take 24 hours to for the restore to process that full server recovery do to the ransomware virus you just downloaded. You are now down for an entire day and likely recovering to the day previously because its was nightly backup. We just lost the ability to work for a day and have to recreated any data created after the last backup which was last night at midnight and I worked for 4 hours today. But hey it was less expensive so who cares we could have paid for a better option with just the outage and time it will take to recreate 4 hours of work.
Recovery Point Objective
This brings us to #2, how much data can you stand to lose in an outage. If you need that document you spent the last 4 hours working on and your server dies. You will either be out the whole document or at least 4 hours worth of work on it if the server crashes and you need to recover it if you are doing a nightly backup of your files. That’s because the last backup ran last night. In the terms of a law firm. One lawyer working on a document for 4 hours at $300/hour = $1200 if they have to recreate that one single document.
With these 2 factors, we can determine what we need. Sometimes a simple file level nightly backup is enough especially for systems that data does not change much on, they systems can be down for a day and if they aren’t mission critical. However, if the needs exceed this, then a disaster recovery solution may make more sense. With a DR solution, RPO and RTO can be set, backups can be taken as “snapshots” at predefined intervals and recovery can much more rapid. Once you have the RPO and RTO calculations we can then determine if the cost to meet PRO and RTO outweigh the cost of an outage and time it takes to recreate the data.
Preventable Loss Scenario
Here is a simple scenario where I will take a hypothetical company and create one issue from each of the above categories analyzing the impacts of not considering Reliability, Scalability and Recovery: We know we can all still do some work when our systems are down even though people express that they can’t so we will estimate the ability to work for each outage while the outage occurs with the % loss of ability to work column.
Company: 100 attorney law firm with average billable hour for each attorney at $300/hour.
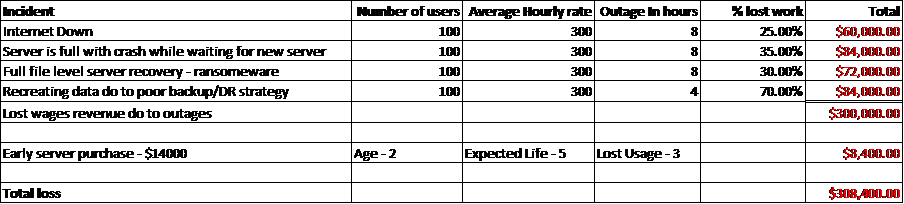
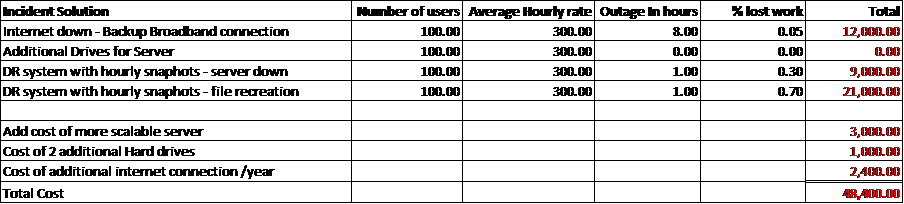
Keep Reading
Is Your Security Built Into Your Operations or Added On Later?
Omni Strategic Technologies
Security issues rarely start with something big. They build quietly. Our new blog post breaks down how this happens and what changes when security is built into how your business runs.
Are You Getting Full Value From Your Tools?
Omni Strategic Technologies
Just because you’re paying for the software doesn’t mean you’re getting full value. For many businesses, features sit unused, workarounds take over and subscriptions renew without a second thought. Our latest blog shows where value slips and how to spot it.

Automation Shortcuts That Save Time and Money
Omni Strategic Technologies
Automation often gets positioned as complex and expensive. In practice, the biggest automation wins usually come from removing the small, repetitive tasks that slow your team down every day.